Over the past couple of months I’ve been using the Onyx Platform with Mastodon C an awful lot.
So this short series I’m going to show you how to build a Onyx Kafka application that consumes a Kafka stream and kicks out the messages to the console. Nothing flashy but more a “here’s the concepts”. In part 1 I’m going to look at getting the Onyx template working and using the Onyx Dashboard. Part 2, and possibly beyond, I’ll then add the Kafka connection and consume from a topic.
Your Shopping List
We’ll look at the Onyx things via git so there’s nothing to download. You will need to download Kafka. Depending on the version of Kafka you are using will determine the type of Onyx Kafka plug in you need.
For Kafka 0.8.x (Currently 0.8.2.2) http://kafka.apache.org/downloads.html then you will require the onyx-kafka-0.8 plugin, for version 0.9.x then you need the onyx-kafka plugin. If you are looking to deploy your Onyx/Kafka system to a Marathon/DCOS setup then I advise you to go for version 0.9.x as that’s what DCOS will give you in the --package-versions from the cli install.
For the rest of this tutorial I’m going to assume a standalone version of Kafka 0.8.2.2, using the supplied Zookeeper instance of 3.4.6.
Onyx Dashboard
Before we do anything do yourself a huge favour and download the Onyx Dashboard, it makes things an awful lot easier to see what’s going on with the cluster.
$ git clone git@github.com:onyx-platform/onyx-dashboard.git
Cloning into 'onyx-dashboard'...
remote: Counting objects: 3815, done.
remote: Total 3815 (delta 0), reused 0 (delta 0), pack-reused 3814
Receiving objects: 100% (3815/3815), 3.37 MiB | 2.30 MiB/s, done.
Resolving deltas: 100% (2079/2079), done.
Checking connectivity... done.
$ cd onyx-dashboard/
$ lein uberjar
Successfully compiled "resources/public/js/app.js" in 76.2 seconds.
Created target/onyx-dashboard-0.9.9.0.jar
Created target/onyx-dashboard.jar
The dashboard will compile, build and be saved as a jar file in the target directory. You may get some ClojureScript warnings but don’t worry about them, it will still build okay. Don’t start anything just yet….
The Onyx Application
The easiest way to create a new Onyx application is to use the Onyx template. It gives you the main structure of the application and the deployment of the peer and the job (more on that later). You don’t have to download anything in advance just use lein to create it.
$ lein new onyx-app testapp -- +docker
Warning: refactor-nrepl requires org.clojure/clojure 1.7.0 or greater.
Warning: refactor-nrepl middleware won't be activated due to missing dependencies.
Generating fresh Onyx app.
Building a new onyx app with: ("+docker")
The template makes some assumptions, which you’d expect, so I’m going to edit the configuration file a bit to make it work under my conditions. From the template the config file (in the resources folder) looks like:
{:env-config
{:onyx/tenancy-id #profile {:default "1"
:docker #env ONYX_ID}
:onyx.bookkeeper/server? true
:onyx.bookkeeper/local-quorum? true
:onyx.bookkeeper/delete-server-data? true
:onyx.bookkeeper/local-quorum-ports [3196 3197 3198]
:onyx.bookkeeper/port 3196
:zookeeper/address #profile {:default "127.0.0.1:2188"
:docker "zookeeper:2181"}
:zookeeper/server? #profile {:default true
:docker false}
:zookeeper.server/port 2188
:onyx.log/config #profile {:default nil
:docker {:level :info}}}
:peer-config
{:onyx/tenancy-id #profile {:default "1"
:docker #env ONYX_ID}
:zookeeper/address #profile {:default "127.0.0.1:2188"
:docker "zookeeper:2181"}
:onyx.peer/job-scheduler :onyx.job-scheduler/greedy
:onyx.peer/zookeeper-timeout 60000
:onyx.messaging/allow-short-circuit? #profile {:default false
:docker true}
:onyx.messaging/impl :aeron
:onyx.messaging/bind-addr #or [#env BIND_ADDR "localhost"]
:onyx.messaging/peer-port 40200
:onyx.messaging.aeron/embedded-driver? #profile {:default true
:docker false}
:onyx.log/config #profile {:default nil
:docker {:level :info}}}}
First of all I’m using my own Zookeeper instance (the one that comes with the Kafka download) so I’m not going to use the embedded one.
:zookeeper/server? #profile {:default true
:docker false}
Now becomes:
:zookeeper/server? #profile {:default false
:docker false}
And the port will need changing too in both the env-config and peer-config blocks..
:zookeeper/address #profile {:default "127.0.0.1:2188"
:docker "zookeeper:2181"}
Now becomes:
:zookeeper/address #profile {:default "127.0.0.1:2181"
:docker "zookeeper:2181"}
I have no need for a BookKeeper server to be running at this moment in time so that can be disabled too.
:onyx.bookkeeper/server? true
Now becomes
:onyx.bookkeeper/server? false
As far as I can see those are all the changes I need to do. Feel free to use the embedded Zookeeper but I prefer to start as I mean to go on and use the version that I’ll be using in the wild.
Next is to the build the basic template, I want to see how it’s going to behave and how to deploy it, which is life gets really interesting. Once again we’ll use Lein to build the application.
$ lein clean ; lein uberjar
Compiling lib-onyx.media-driver
Compiling testapp.core
Compiling lib-onyx.media-driver
Compiling testapp.core
Created target/testapp-0.1.0-SNAPSHOT.jar
Created target/peer.jar
All built okay. The next step is to start everything up.
Running the Application
Before I start here’s something to clear up. Jobs are submitted to Zookeeper, they don’t require any peers running at the time, they do however require the node structure to exist within Zookeeper, meaning that if Onyx peers have never run before then the job will not deploy but rather throw an exception.
When a peer is then started it will go to Zookeeper looking for jobs to run. And if it took my colleagues “a while for the penny to drop” well firstly there’s hope for me yet and secondly it may have been buried in the docs somewhere.
I’m not going to submit data to the job, I just want to get the job running and get a peer running too. Then I’ll inspect the dashboard to see what’s going on.
STARTING ZOOKEEPER
I’m going to my Kafka distribution and going to start the Zookeeper instance. On my Mac OSX developer environment I start it as root so there’s no faffing about with permissions. Yes I know Docker exists… that comes later.
bin/zookeeper-server-start.sh config/zookeeper.properties
STARTING A PEER
Open up a new terminal window and go to the application directory again. I’m going to start a single peer up.
$ java -cp target/peer.jar testapp.core start-peers 1 -c resources/config.edn
Starting peer-group
Starting env
Starting peers
Attempting to connect to Zookeeper @ 127.0.0.1:2181
Started peers. Blocking forever.
Once you see “Started peers. Blocking forever” we have a registered peer on the cluster.
SUBMITTING THE JOB
I can submit a job to Zookeeper for a running peer to pick it up later if the node structure exists, as discussed earlier. Don’t forget that Zookeeper will persist the job when a peer is shutdown. So in theory you only need to submit the job once.
Saying all that: IF you have never started a peer before then there’s no Onyx job scheduler registered in Zookeeper and this will cause you pain as the job will have no scheduler to check against, it will time out.
$ java -cp target/peer.jar testapp.core submit-job "basic-job" -c resources/config.edn
16-Jul-31 09:45:50 jasebellmacmini.local INFO [onyx.log.zookeeper] - Starting ZooKeeper client connection. If Onyx hangs here it may indicate a difficulty connecting to ZooKeeper.
16-Jul-31 09:45:50 jasebellmacmini.local INFO [onyx.log.zookeeper] - Stopping ZooKeeper client connection
Successfully submitted job: #uuid "0201c86b-93ff-4470-9e58-7c2f8a78e080"
Blocking on job completion...
16-Jul-31 09:45:51 jasebellmacmini.local INFO [onyx.log.zookeeper] - Starting ZooKeeper client connection. If Onyx hangs here it may indicate a difficulty connecting to ZooKeeper.
16-Jul-31 09:45:51 jasebellmacmini.local INFO [onyx.log.zookeeper] - Starting ZooKeeper client connection. If Onyx hangs here it may indicate a difficulty connecting to ZooKeeper.
Once running it will sit there merrily waiting for the job to complete.
STARTING THE DASHBOARD
To confirm my assumptions I’m going to fire up the dashboard and have a look around. All I need to do is start up the jar file and pass in the Zookeeper address.
$ java -jar target/onyx-dashboard.jar localhost:2181
Starting Sente
Starting HTTP Server
Http-kit server is running at http://localhost:3000/
Once started we can open a browser and have a look at the dashboard.
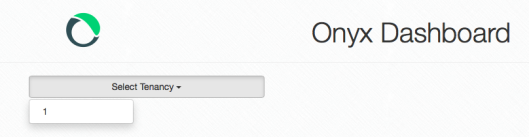
From the drop down you will see a list of the running peer specifications. I’ve only got the one running. When selected it will load up the information about the peer and the added jobs.
Inspecting the Peer and Job
So I’ve a browser open and I’ve loaded up http://localhost:3000
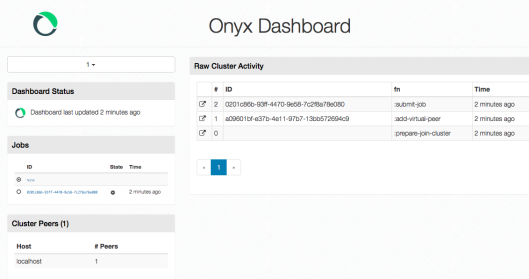
The raw cluster activity shows us everything that’s happening. Click on the left hand side of the log entry will show you more information. The jobs are listed on the left hand side of the page. You can see there’s only one submitted job, if you click on it will show you more detail.
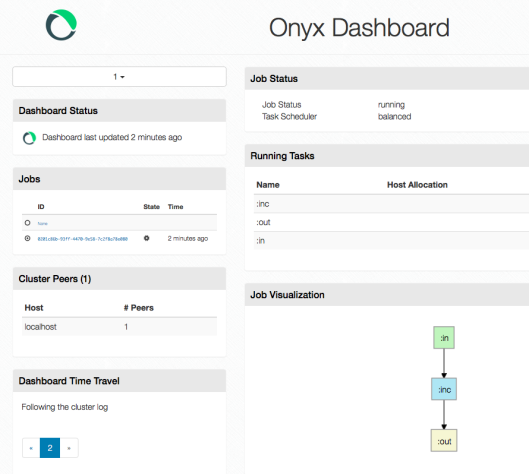
So we have a running job, you can also see the workflow of the job with it’s input, inc and output flows.
In Part 2
I’ll take this basic job and make it consume a Kafka topic and show the contents of the message load. I may even make it do something useful.
Share this article